Make your existing solution tastier with serverless salt: NoOps
This article is the fourth in a series on “serverless.” I recommend starting at the beginning of the series, as I introduce concepts incrementally. The links to previous articles are included here:
- Introduction
- Feasibility
- Distributed system
- NoOps
- ...
In the previous articles, I demonstrated the benefits and challenges of serverless integration for business applications and illustrated them with an example based on the Bonita platform. As you know by now if you have been reading along, the main benefit of serverless is to abstract infrastructure with ephemeral containers using a FaaS service on the cloud.
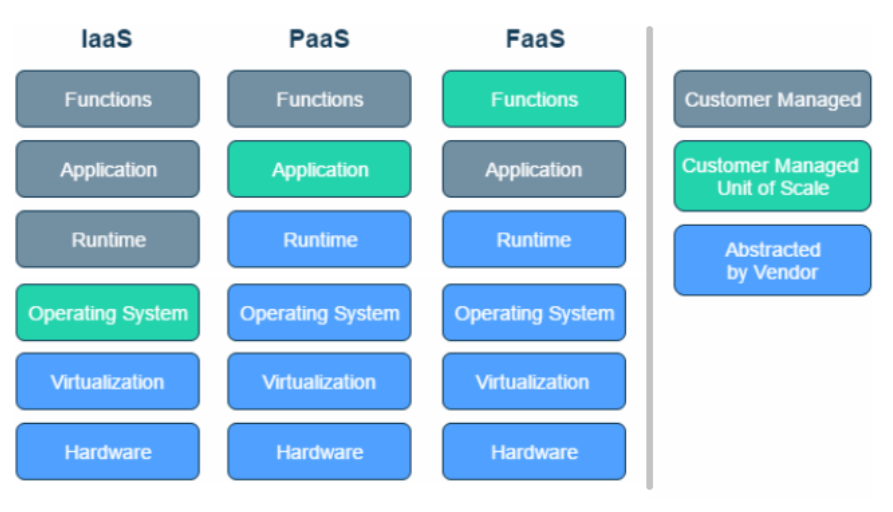
For a distributed application that needs to scale, the challenge of automating its operations has to be overcome. Most applications based on microservices manage this using technologies such as Kubernetes. But what could be considered as a “good-to-have” in the case of a microservices-based application is “mandatory” in the case of a serverless-based application. The unit of scale is basically ten, sometimes several hundred, times more granular. In this article, I’ll show how I automate the administration of the serverless function used in the business application example - objective NoOps!
As in the previous articles, you can follow along in detail with the development resources I share as a single archive file named “level3-1.0.zip” in the release “level3-1.0” of a dedicated GitHub project. The “Serverless_Level3-1.0.bos” BOS file can be imported in any 7.7.4 or higher version of the Bonita Studio.
Architecture
Like many platforms, the main component of the Bonita architecture is its engine. It handles execution of the business application processes and is composed of many APIs and services.
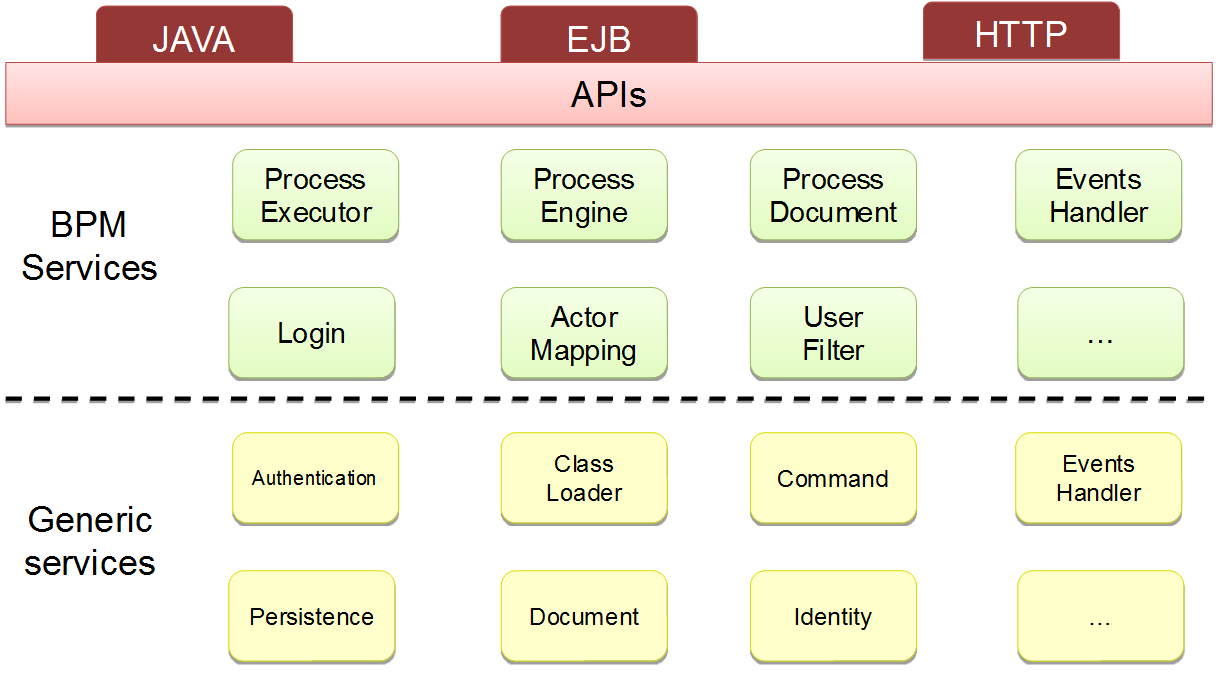
A useful thing about Bonita is its extensibility when it comes to these APIs and services. Similar to the Spring framework, it uses the powerful concept of the Inversion of Control (IoC). This is what I use to extend the default behavior of the platform.
Service
In short, I want the platform to deploy/delete the serverless functions associated with the connectors used in the process definitions of the application at deployment/undeployment time.
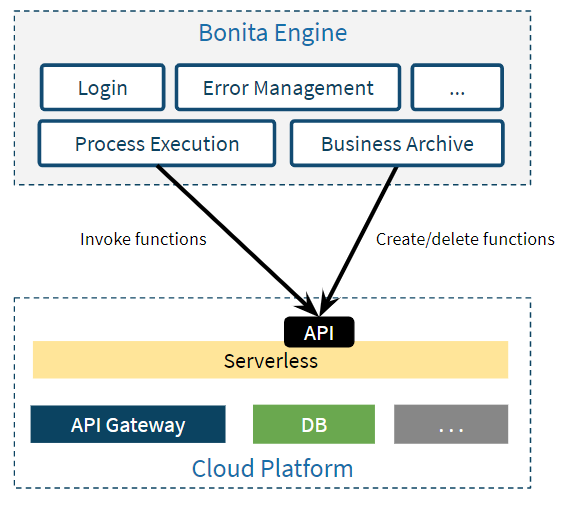
We’ve already used the Process Execution service to handle the serverless function invocations via connector executions in the application processes (see previous articles). What we are missing here is an extension of the Business Archive service to automatically create/delete functions.
Implementation
I cloned the GitHub repository related to the platform engine and imported it into a workspace of Eclipse IDE. It is pretty simple to do because these are mavenized Java projects.
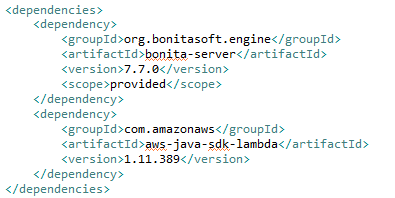
Then I created new projects with Bonita and AWS dependencies.
I created a new class that extends the default service implementation used by the platform BusinessArchiveServiceImpl. I also added a method here to extract the information from the process definition design that is necessary to complete the automatic operations at deployment/deletion time.
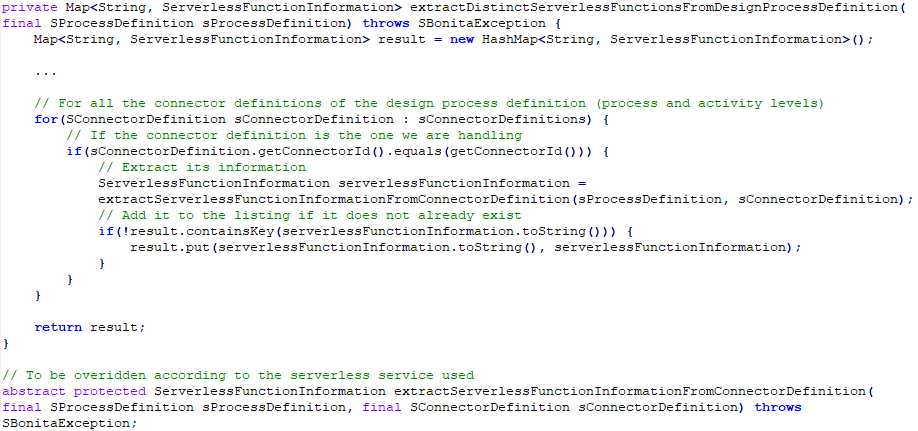
I extended the two default methods used at deployment and deletion time to automatically create and delete the serverless functions associated with the process design.
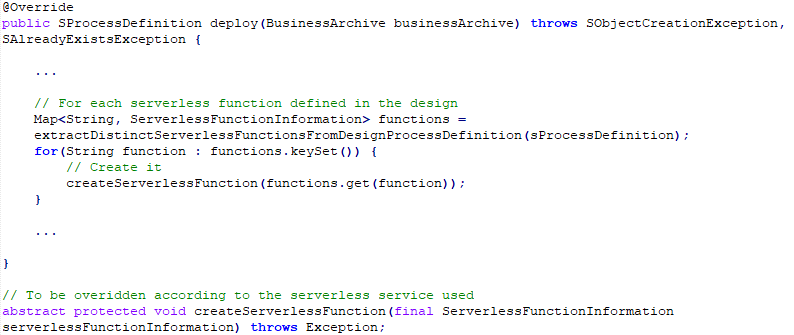
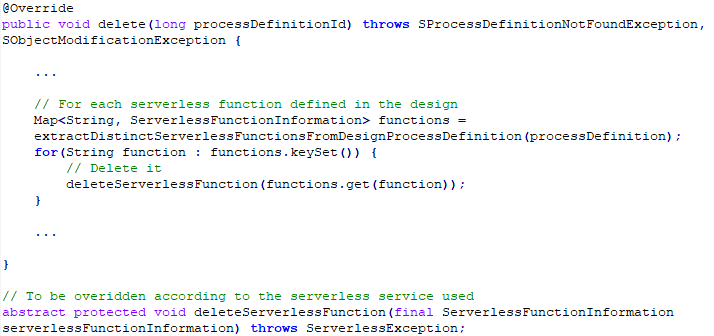
You may have noticed that there are abstract methods. I used this to separate what is generic and what is specific to serverless providers. I extended these abstract methods for AWS Lambda as this is what I used in the example.

Deployment
The implementation of the extension done, I built a shaded JAR using maven to avoid any dependence conflicts and I added it to the classpath of the bonita application in the application server (Tomcat in this example). You can find the compiled artifact “bonita-serverless-ext-aws-lambda-0.0.1-shaded.jar” in the ”level3-1.0.zip” archive file.
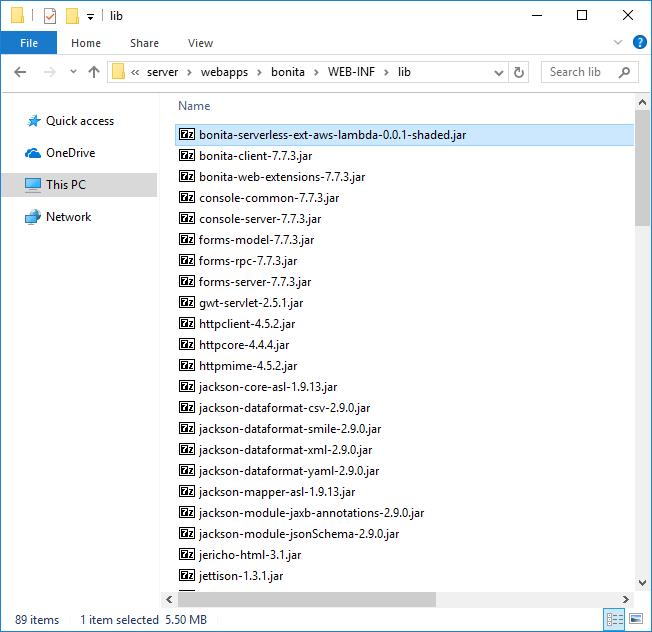
To leverage the extended behavior implemented in this library, I needed to edit the platform configuration. To avoid File System (FS) dependencies, the configuration is stored in the engine database. Good thing I can use the provided tool to pull the current configuration files from the database to the FS. From there I can apply the two necessary updates:
- businessArchiveService
The default configuration of the related bean looks like this
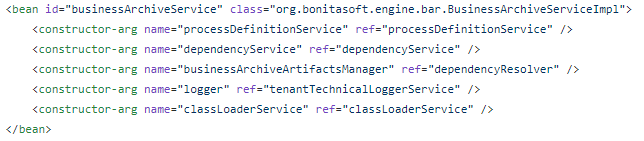
I changed it to use the extended implementation with the additional constructor argument named expressionResolverService.
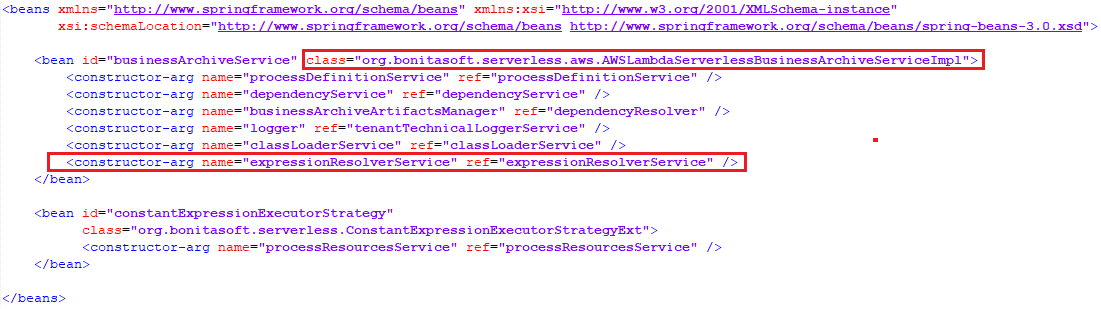
- constantExpressionExecutorStrategy
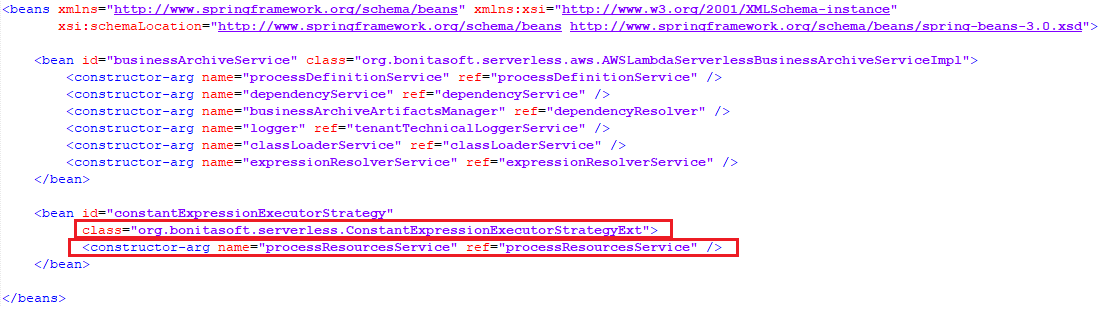
The default configuration of the related bean looks like this

I also changed it to use the extended implementation with the additional constructor argument named expressionResolverService.
The configuration modified, I can use the provided tool again to push it back from the FS to the database. It is only at this time that I restart the platform to apply the configuration and continue. You can find the edited configuration file “bonita-tenants-custom.xml” in the ”level3-1.0.zip” archive file.
Connector
Because I need to provide more information about the serverless function to enable automatic operations, I created a new connector definition that extends the one I used in the previous article. I used the id “aws-lambda-auto” again as this is what I used in the service extension to filter. The main modification is in the definition of the inputs of the connector. I added:
- jar: process resource path of the JAR that contains the serverless function code
- role: Amazon Resource Names (ARN) of the role to be used
- handler: what method to invoke as part of the serverless function
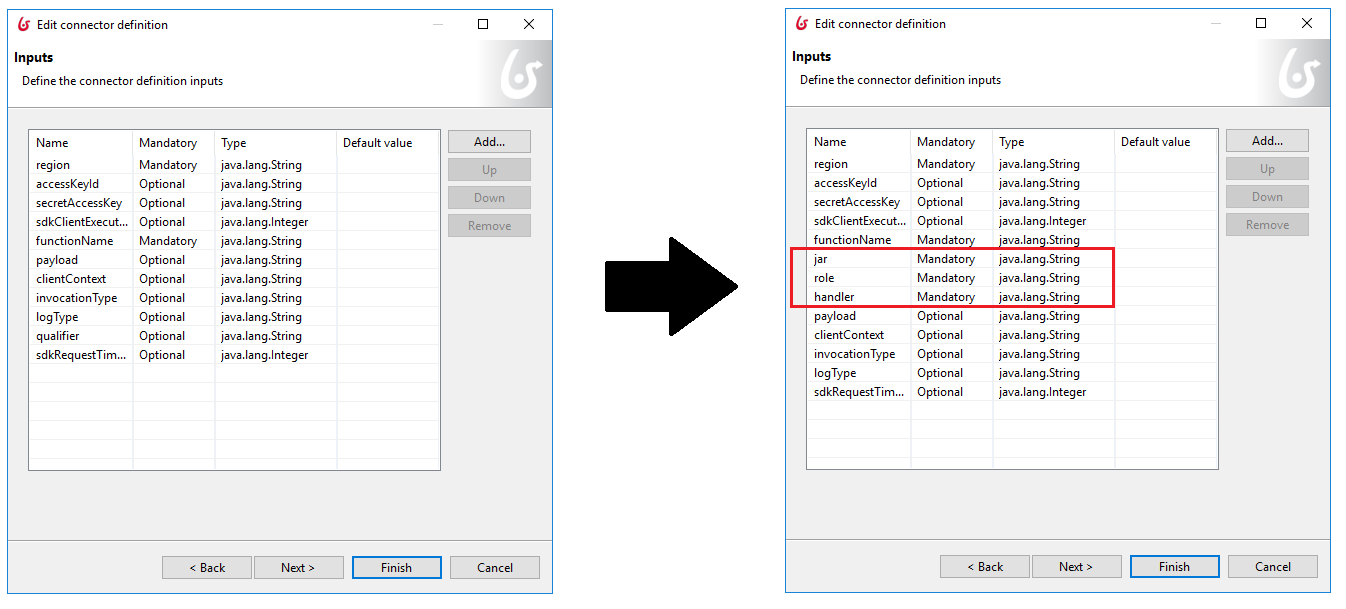
The connector implementation remains the same as before though. The point of adding these inputs is to be used by the service extension at deployment/deletion time. I do not need to change anything in the way the connector executes.
Application
The new version of the application did not require too much editing. I just needed to configure the connector providing the new inputs with the right values:
- jar: forms/resources/aws-lambda-example-0.0.1-jar-with-dependencies.jar
- role: arn:aws:iam::
:role/service-role/ - handler: org.bonitasoft.serverless.aws.RequestHandlerExample::handleRequest
The AWS Lambda serverless function JAR remains the same as the one I used in the previous article. I added it in the process resources to easily store it and make it accessible at runtime by the service extension. A great improvement would be to provide the code as text instead of a compiled JAR which is specific to Java. This would make all AWS Lambda runtimes easily available, your developers would love it!
Run it
I deployed the application with all its dependencies just like I would do for any other. It takes a bit more time than usual because the AWS Lambda function creation takes a few extra seconds. Some information about the serverless function creation is provided in the platform logs.
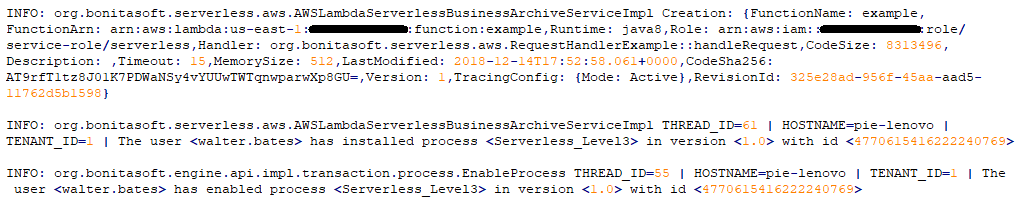
The deployed application can be used like a regular one - the result is the same as in the previous article.
If I remove the application and its dependencies, it also takes a bit more time than usual because the AWS Lambda function deletion takes a few extra seconds again. Some information about the serverless function deletion is provided in the platform logs.

This confirms that I have a platform that automatically deals with serverless function administration, based on the business application definition alone. How sweet is this?

Obviously, there will never be anything like actual NoOps and this proof of concept is specific to business applications built with the Bonita platform. But the main idea was to inspire you.
- For Bonita users: industrialize and you will scale your serverless developments
- For everyone: I am sure a similar thing can be done for other platforms or applications you may have, if it is extensibile enough.
In the next article of this series I will focus on the vendor lock-in issue and practical use cases, so check for updates!
I would appreciate your feedback in the comments: enhancements, new topics to cover, etc. If you like what you read, let us know and we will spread the word!